
- 1:0x00 综述
- 2:0x01 直接映射Cache
- 3:0x02 组相连Cache
- 4:0x03 全相连Cache
- 5:0x04 Cache的写入策略
- 6:0x05 Cache的替换策略
- 6.1:近期最少使用法(LRU)
- 6.2:随机替换
- 7:0x06 提高Cache的性能
- 7.1:写缓存(Write Buffer)
- 7.2:流水化(Pipelined Cache)
- 7.3:多级结构(Multilevel Cache)
- 7.4:Victim Cache
- 8:0x07 预取(Prefetching)
- 8.1:硬件预取
- 8.2:软件预取
- 9:0x08 多端口Cache
- 9.1:True Multi-port
- 9.2:Multiple Cache Copies
- 9.3:Multi-banking
- 10:0x09 超标量处理器的取指令
0x00 综述
本文主要参考了姚永斌的《超标量处理器设计》
Cache存在的意义在于解决时间相关性与空间相关性问题。
目前现代的超标量处理器都是哈佛结构,为了让高速处理器匹配低速的存储器,通常采用的多级Cache结构。其中,通常L1 Cache分为ICache与DCache(或写作I$与D$),分别用于指令和数据。ICache的设计一般只需要考虑读取的情况,而DCache还需要考虑写入的情况。
由于L1 Cache是最靠近处理器的存储器,因此其速度需要最大程度接近处理器的速度,这限制了其容量,同时为了达到这个目的,L1 Cache一般都是使用SRAM实现。
L2 Cache容量则更大一些,被L1 ICache与DCache共享。在单核处理器中,一般都是两级Cache,而在多核处理器中,一般都是三级Cache,其中L2 Cache属于单核核心,而L3 Cache则被所有核心共享。
相对于一般的处理器,超标量处理器对Cache的要求更高:对于ICache而言,需要实现每周期读取多条指令;对于DCache而言,则需要其每周期支持多条load/store指令的访问,也就是需要多端口的设计。尽管在超标量处理器中,多端口的部件有很多,但是这些器件本身的容量并不大,因此采用多端口设计也不会占用太大空间。而DCache的容量本身比较大,直接采用多端口的设计,其就会占用过大的硅片面积,并因此产生过大的访问延迟。由于load指令一般处于相关性的顶端,因此这会给处理器的性能带来负面的影响,因此ICache与DCache的设计思路是不一样的。
而L2 Cache则并不需要多端口的设计,延迟也不如L1 Cache重要,最重要的则是其命中率,因为在两级Cache的架构中,若L2 Cache无法命中,一般就需要去访问物理内存(一般是DRAM),其访问时间会非常长。
Cache由两部分组成:Tag与Data,其中Data部分用来保存一片连续地址的数据,而Tag部分则存储这片连续数据的公共地址,一个Tag与其对应的Data构成的一行称为一个Cache Line,而Cache Line中的数据部分称为数据块(Data Block),如果一个数据可以存储在Cache中的多个地方(一般是多路设计的情况下),这些被同一个地址找到的多个Cache Line称为一个Cache Set。
Cache分为三种主要的实现方式:直接映射(Direct-mapped) Cache、组相连(Set-associative) Cache以及组相连(Fully-associative)Cache。
但不管是哪种实现方式,由于Cache的容量有限,其不可能保存存储器中的全部数据,因此必然会发生Cache缺失(Cache miss)问题。
影响Cache缺失的原因可以概括为以下三种:
- 强制缺失(Compulsory):由于Cache只是缓存以前访问过的内容,因此第一次被访问的指令或数据肯定不会在Cache中,因此,这个缺失是肯定会发生的,不过可以采用预取(Prefetching)技术在一定程度上降低这种缺失发生的频率。
- 容量缺失(Capcity):Cache容量越大,就可以缓存更多的内容,因此容量是影响Cache缺失发生频率的一个关键因素。
- 冲突缺失(Conflict):为了解决多个数据映射到Cache中同一个位置的情况,一般使用组相连结构的Cache,但由于面积和延迟限制,其相连度不可能很高。若一个程序频繁使用的几个数据同属于一个Cache set,同时其数量高于相连度,就会导致缺失率大大提升,为此,可以使用Victim Cache来缓解这个问题。
0x01 直接映射Cache
这种结构的Cache是最容易实现的一种Cache,可以认为是只有一个Way的组相连Cache,处理器访问存储器的地址会被分为三个部分:Tag、Index以及Block Offset,结构如下图所示:
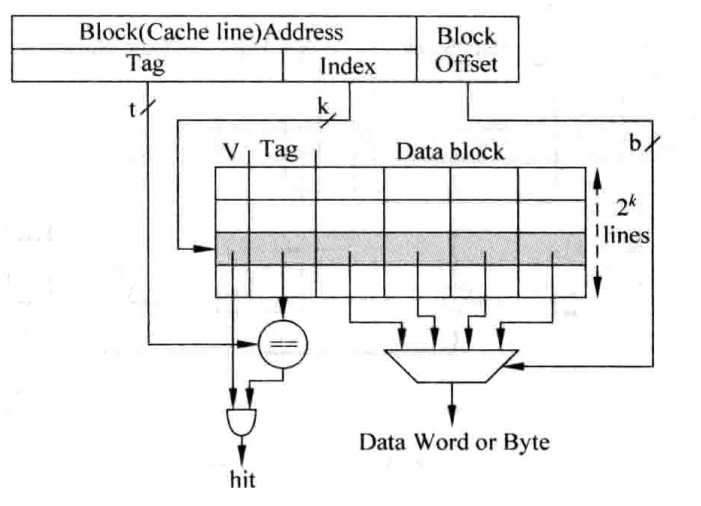
其之所以被称作直接映射,是因为地址中的Index字段直接作为Cache Line地址,这样,对于所有Index相同的存储器地址,都会寻址到同一个Cache Line,这就产生了冲突,这也是直接映射结构Cache的一大缺点。这种结构甚至简单到不需要替换算法,但是其执行效率也是最低的,现代处理器中很少会使用这种方式了。
0x02 组相连Cache
这种方式的提出是为了解决直接映射Cache最大的一个问题:Index相同的数据只能放在一个Cache Line中。
组相连Cache使用了Cache Set的概念,一个Cache Set包含多个Cache Line,这些Cache Line的Index都相同。当一个Cache Set中的某一个Cache Line被占用,而另一个Cache Line空闲时,就不必踢掉已有的数据,而是使用空闲的槽位,这样就大大降低了缺失率,而一个Cache Set所包含的Cache Line就被成为这个Cache的相连度。例如,若一个Cache Set包含两个Cache Line,则这个Cache称为2路组相连Cache,结构如下图所示:
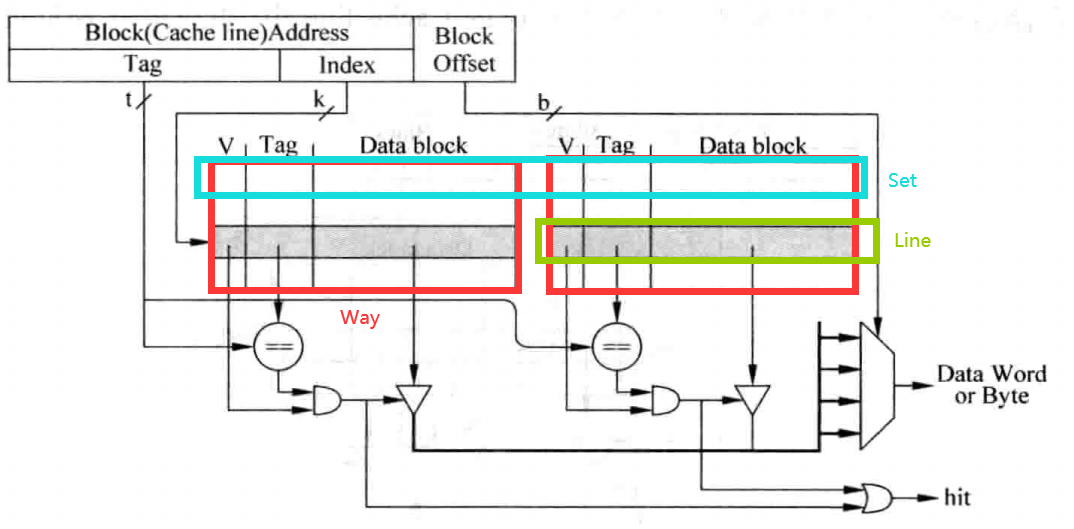
上图中可以看到,Cache被分成了两个存储区域。其中,一个存储区域叫做一“路”。
可以看到,由于需要从多个Cache Line中选择一个匹配的结果,因此这种实现方式相对于直接映射结构的Cache而言延迟会更大,有时候甚至需要将其访问过程流水化,以减少对处理器频率的影响,这样会导致load指令的延迟(Latency)增大,一定程度上影响了处理器的执行效率,但是这种方式的优点在于,它可以显著地减少Cache缺失发生的频率,因此在现代的处理器中得到了广泛的应用。
在实际实现中,Tag和Data部分实际上是分开的,分别叫做Tag SRAM和Data SRAM。
对于这种实现,可以采用并行访问(即同时访问Tag SRAM和Data SRAM)及串行访问(即先访问Tag SRAM再访问Data SRAM)方法。
对于并行访问方法而言,在读取Tag的同时,需要将每一路Index对应的的Data部分全部读取出来,然后送到多路选择器上,这个多路选择器受到Tag比较结果的控制,选出对应的Data Block,然后根据存储器地址中Block Offset的值,选择出合适的字节,一般将选择字节的这个过程称为数据对齐(Data Alignment)。Cache的访问一般都是处理器中的关键路径(Critical Path),这种方式在现实中如果在一个周期内完成访问的话会占据很大的延迟,因此就需要进行流水化处理。对于ICache而言,其影响不会太大,依然可以实现每周期读取指令的效果;而对于DCache而言,则会增大load指令的延迟,从而对处理器的性能造成负面影响,以下是工作原理及一个划分示例:
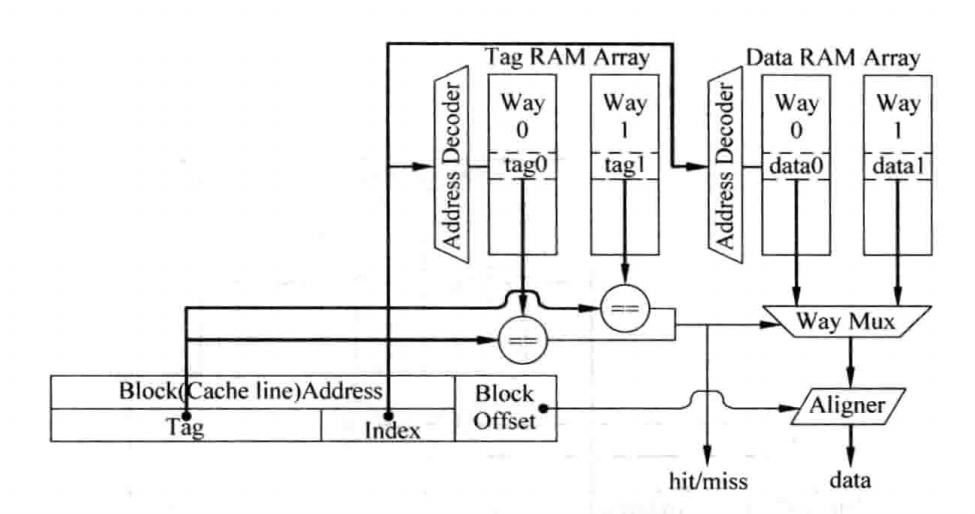
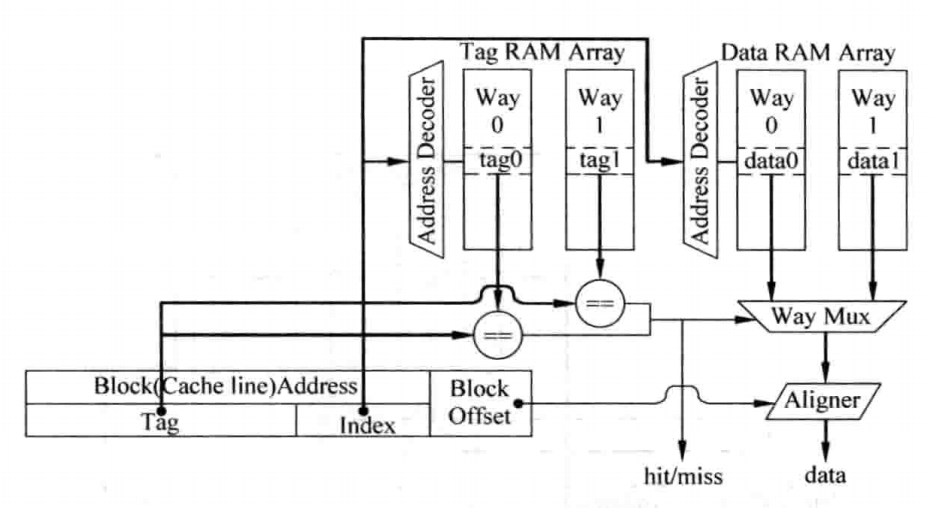
对于串行访问方法而言,首先访问Tag SRAM,根据Tag比较的结果,就可以知道数据部分中哪一路的数据是需要被访问的,此时可以将其它SRAM的使能信号都可以被置为无效,这样就可以节省很多功耗,当然,这种方式延迟会更大,按照上面的方式进行流水化,会导致新增一个流水周期:
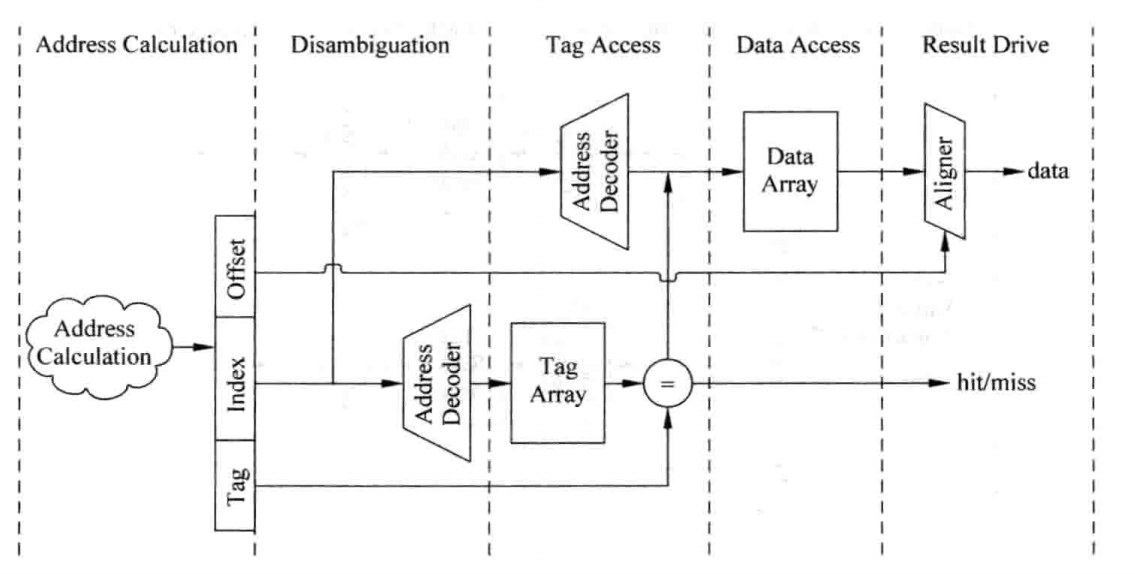
并行访问方式相比于串行访问方式而言,会有较低的时钟频率和较高的功耗,但是访问Cache的时间缩短了一个周期,但考虑在乱序执行的超标量处理器中,可以将访问Cache的这段时间通过填充其它的指令而掩盖起来,所以对于超标量处理器来说,当Cache的访问处于处理器的关键路径上时,可以使用串行访问的方式来提高时钟频率,同时并不会由于访问Cache的时间增加了一个周期而引起性能的明显降低;而对于顺序的处理器而言,并行访问方式则相对来说更合适。
0x03 全相连Cache
这种Cache实际上可以认为是只有一个Set的组相连Cache,在这种Cache中,存储器地址中将不再有Index部分,因为数据可以放在任何一个Cache Line中,这实际上就是一个内容寻址的存储器(Content Address Memory,CAM),在实际设计中,通常采用Tag CAM + Data SRAM的结构,以减少CAM过大所引起的走线延迟问题,并因此导致这种结构的Cache一般容量都不会太大,多见于TLB的设计中。
0x04 Cache的写入策略
由于一般ICache不会被直接写入内容,即使有自修改(Self-modifying),也通常是借助DCache实现的,因此,这里仅讨论DCache的写入策略。
DCache的写入策略可以总结为写通(Write Through)和写回(Write Back)。所谓写通是指,对Dache的所有写入操作会被同时在其下级存储器上执行,但由于下级存储器的访问时间一般来说比较长,而store指令在程序中出现的频率又比较高,这样必然会导致处理器的执行效率下降;所谓写回则是指,数据写到DCache后,对应的Cache Line会被标记为Dirty,只有当这个Cache Line被替换时,其数据才会写入下级存储器,这种方式会大大提升处理器的执行效率,但是会造成DCache与下级存储器的数据不一致(Non-consistent)问题。
上面的讨论都是假设在写DCache时,要写入的地址已经存在与DCache中,但事实上这个地址有可能并不存在于DCache中,这就发生了写缺失(Write Miss),这种情况的处理策略也可以总结为两种:Non-Write Allocate与Write Allocate。所谓Non-Write Allocate是指,直接将数据写到下级存储器中,而并不写到DCache中;所谓Write Allocate是指,首先将写入地址对应的整个数据块取回DCache中,然后再将写入到DCache中的数据合并到这个数据块中,之所以需要先取回,是因为一次写操作的数据量远远小于一个数据块的大小,如果不进行取回则直接写入DCache并标记Dirty,后期写回处理器时,必然会造成其周围的数据被破坏。一般来说,写通总是配合Non-Write Allocate使用,而Write Back则通常和Write Allocate配合使用。可以看出,Write Back与Write Allocate配合的方式设计复杂度是最高的,但是其效率也是最好的。
0x05 Cache的替换策略
首先,只有组相连和全相连Cache才需要考虑替换策略,其次,只有当一个Cache Set对应的所有的Cache Line都用完(对于组相连)或所有Cache Line都用完(对于全相连)时,才需要考虑替换策略(否则直接将数据填到空闲Cache Line即可,不需要做替换),这里介绍几种最常用的替换算法。
近期最少使用法(LRU)
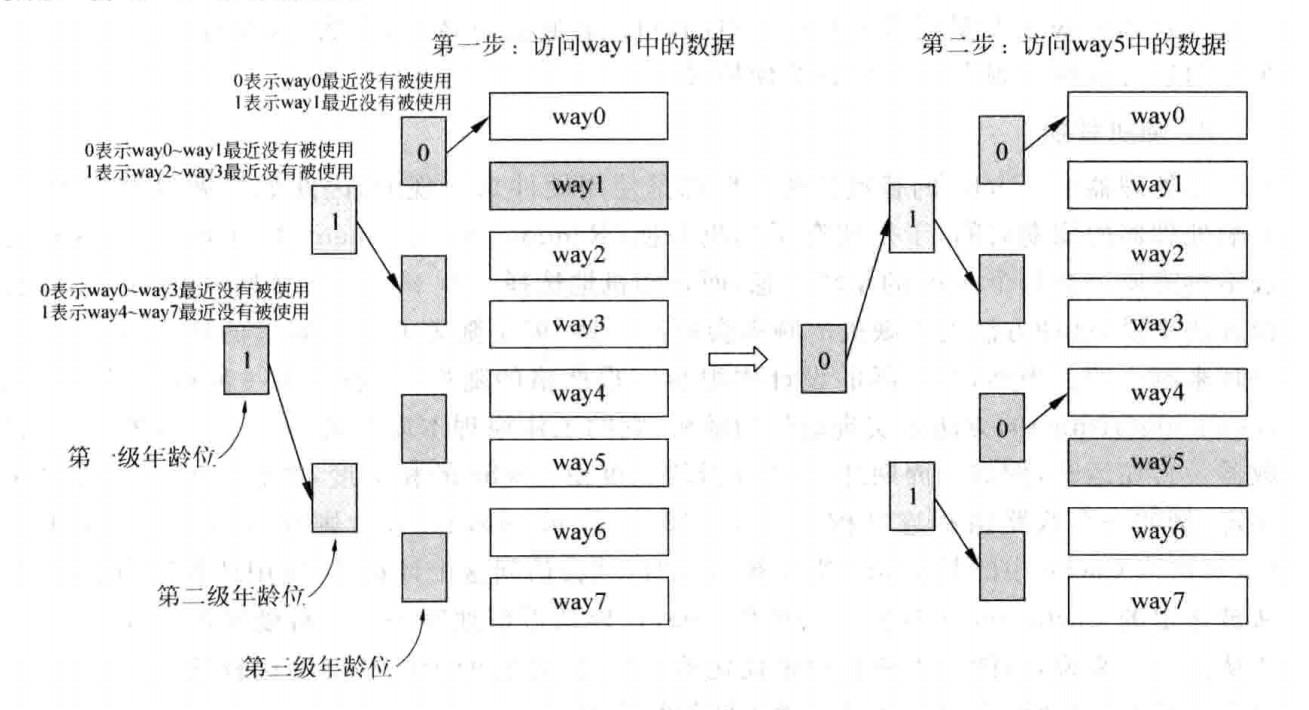
这种方法会选择最近被使用次数最少的Cache Line,为此,需要给每个Cache Line设置一个年龄(Age)字段,每当一个Cache Line被访问时,其对应的Age字段就会增加,或者减少其它Cache Line的年龄值,这样在替换时,只需要选择年龄值最小的那个Cache Line即可。但是,随着Cache相关度的增加,这种策略实现非常昂贵,因此,对于相关性很高的Cache,通常都是使用伪LRU方法,即将所有的way进行分组,每一组使用一个1bit的年龄部分,同时采用树状方式多级分组,通常采用二叉树结构。例如对于一个8路组相连Cache,采用如下方式实现伪LRU:
随机替换
由于Cache的替换算法一般使用硬件实现,因此不可能做的很复杂。这种方法不需要记录每个way的年龄信息,而是顾名思义,随机选择一个way进行替换。尽管相比于LRU替换而言,这种方式发生缺失的频率会更高一些,但随着Ccache容量的增大,这个差距是越来越小的。事实上,在实际的设计中很难实现严格的随机,而是使用时钟算法(Clock Algorithm)来实现近似的随机。所谓时钟算法,就是使用一个计数器,每替换一次Cache Line,这个计数器就加一,利用计数器当前的值,从被选定的Cache Set中找到要替换的Cache Line。这是一种不错的折中方法。
0x06 提高Cache的性能
在实际的的处理器中,会采用一些更复杂的方法提高Cache的性能,包括写缓存(Write Buffer)、流水化(Pipelined Cache)、多级结构(Multilevel Cache)、Victim Cache和预取(Prefetching)等方法,除此之外,对于超标量处理器而言,还有非阻塞(Non-blocking)Cache、关键字优先(Critical Word First)和提前开始(Early Restart)等方法,这里主要介绍前几种方法。
写缓存(Write Buffer)
我们知道,在采用写回策略的Cache进行替换时,需要首先将Dirty状态的Cache Line写到下级存储器中,然后才能从下级存储器中读取缺失的数据,由于下级存储器的访问时间都比较长,这种串行的过程会导致DCache发生缺失的处理时间变得很长,此时就可以采用写缓存来解决这个问题:Dirty状态的Cache Line首先放到写缓存中,等到下级存储器空闲的时候,才会将写缓存中的数据写到下级存储器中,过程如下:
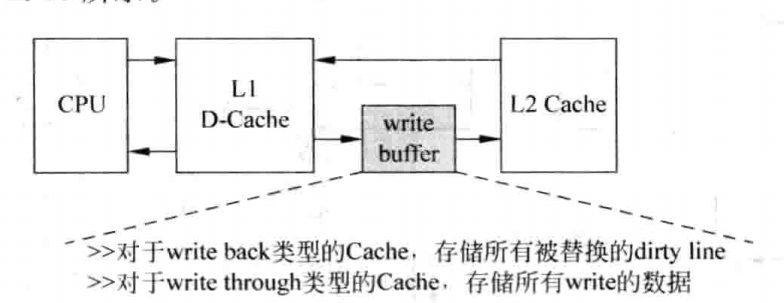
当然,采用这种设计,会增加系统设计的复杂度:在读取DCache发生缺失时,不仅需要查找下级存储器,还需要查找写缓存,因为写缓存中的数据相比下级存储器而言更新,这需要在写缓存中加入CAM电路。
这种设计除了用于写回策略,同时也非常适合用于写通策略。
流水化(Pipelined Cache)
相比于读取数据时使用并行访问的策略访问Tag SRAM与Data SRAM,在写数据时,读取Tag SRAM和写Data SRAM的操作只能串行地进行。只有通过Tag比较看,确定要写的地址在Cache中之后,才可以写Data SRAM,在主频比较高的处理器中,这些操作很难在一个周期内完成,这就需要对DCache的写操作进行流水化,当然,这也会导致在load时,增加前馈路径数量,导致系统复杂性提升。
多级结构(Multilevel Cache)
现代处理器希望有一种容量大,同时速度又很快的存储器,但事实上,容量和速度是一对相互制约的因素,容量大必然速度慢,反之亦然。为了近似地达到这个目标,可以使用多级结构的Cache,即在CPU和物理存储器之间加入多级Cache,这些Cache的大小随着与CPU的距离增大而增大,同时速度随着与CPU的距离增大而减小,从而构建出一个Memory Hierachy。通常情况下,L1 Cache容量很小,能够和处理器内核保持在同样的速度等级,L2 Cache的访问则需要消耗处理器的几个时钟周期,但容量要更大一些,以此类推。一般来说,L2 Cache会使用写回的方式,而L1 Cache则采用写通的方式,这样可以在不损失太多性能的情况下简化流水线的设计,尤其是在多核环境下简化存储器一致性同步设计。
这里还存在两个概念,分别是Inclusive与Exclusive,其定义如下:
- Inclusive:如果下级Cache包括了上级Cache中的所有内容,则称下级Cache是Inclusive的。
- Exclusive:如果下级Cache和上级Cache的内容互不相同,则称下级Cache是Exclusive的。
例如L1 Cache与L2 Cache采用Inclusive与Exclusive的形式如下图所示:
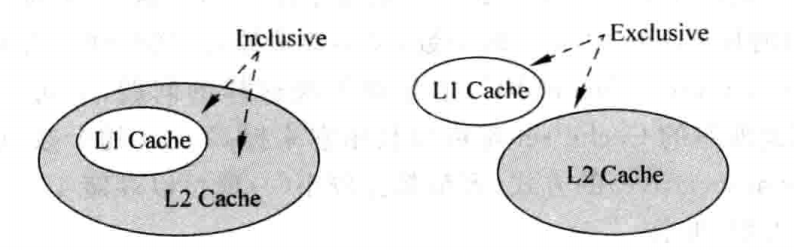
Inclusive的缺点在于,其一份数据同时保存在两个地方,比较浪费硬件资源,但其最大的优点在于,简化了一致性(coherence)的管理,例如在多核的处理器中,当其中一个处理器改变了存储器中一个地址的数据时,如果在其它处理器的私有Cache(一般在多核处理器中,L1 Cache和L2 Cache都是私有的)中也保存了这个地址的数据,那么需要将它们置为无效,以避免这些处理器使用到错误的数据。如果是Inclusive类型的Cache,那么只需要检查最低一级的Cache即可,否则需要同时检查L1与L2 Cache,由于L1 Cache在处理器流水线的关键路径上,这会影响到处理器的执行效率;而Exclusive类型的Cache避免了硬件的浪费,由于Cache容量的大小直接影响处理器的性能,在同样的硅片面积下,Exclusive类型的Cache可以获得更多可用的容量,在一定程度上提高了处理器的性能,不过现代的大多数处理器都采用了Inclusive类型的Cache。
Victim Cache
有时候Cache中刚刚被替换掉的数据可能马上又要被使用,例如若一个CPU使用了2路组相连的DCache,而一个程序频繁使用的3个数据又恰好位于同一个Cache Set中,那么就会导致一个way中的数据经常被替换掉,然后又经常被写回Cache,这会导致处理器的执行效率大大下降,而为此增加way的个数通常又是不值得的,因为其它Cache Set未必有这样的特征,因此采用Victim Cache保存最近Cache替换掉的数据。通常Victim Cache采用全相连的方式,其容量都比较小(一般可以存储4~16个数据),其原理如下:
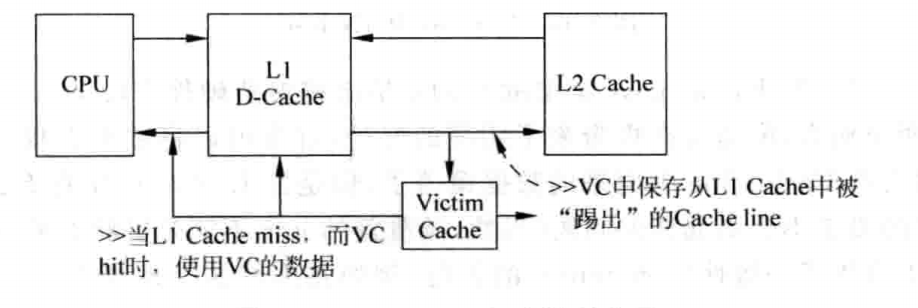
现代的大多数处理器中都采用了Victim Cache。
还有一种类似的设计思路,称为Filter Cache,只不过它放在Cache的前面,而Victim Cache则是在Cache之后。当一个数据第一次被使用时,它并不会马上被放到Cache中,而是首先放到Filter Cache中,等到这个数据再次被使用时,它才会被搬移到Cache中,这样做可以防止那些偶然被使用的数据占据Cache,从而提高Cache的利用效率,其原理如下:
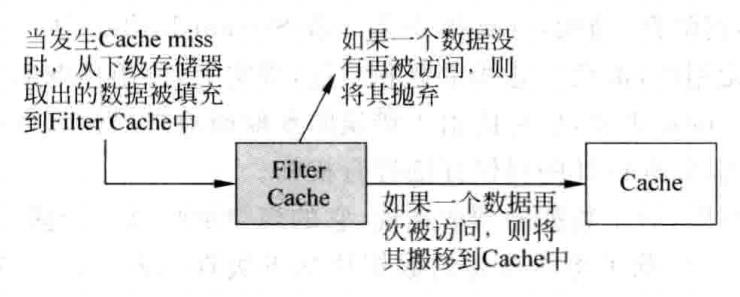
0x07 预取(Prefetching)
预取技术主要是减少因为Compulsory所引起的缺失率上升的问题,即采用预测技术,猜测处理器在以后可能使用什么指令或数据,然后将其提前放到Cache中,这个过程可以用硬件完成,也可以用软件完成。
硬件预取
通常来说,猜测后续会执行什么指令是相对容易的,因为程序本身就是串行执行的,因此在访问ICache中的一个数据块的时候,将它后面的数据块也取出来放到ICache中就可以了,但由于程序存在分支,猜测有可能出错,导致不会使用的指令进入ICache,从而污染了ICache,为此,可以将预取的指令放到一个单独的缓存中,在确定猜测无误时,再将数据搬移到ICache中。
而预测后续需要的数据块则困难的多,因为规律更难以捕捉,Intel Core i7采用了类似于指令预取一样,直接预取下一个数据块的方法,而Intel Pentium 4和IBM Power5处理器,则采用了一种称为跨距预取(Strided Prefetching)的方法,即使用硬件观测程序中使用数据的规律,例如:若第一个数据位于地址a处,第二个数据位于地址a + 128处,第三个数据位于a + 256处,那么硬件就会预测下一个数据位于地址a + 384,并进行预取操作,甚至会将a + 512、a + 640、a + 768等数据都进行预取,例如IBM Power5就会提前预取12个数据块,这种预取策略过于激进,对于一些程序,它有可能大幅提高执行速度,但也可能对其它程序带来一些负面影响。
软件预取
因为硬件难以预测程序访问数据的规律,而编译器(Compiler)却可以比较轻易地获得这个信息,如果在指令集中设有预取指令,那么编译器就可以直接控制程序进行预取,这就是软件预取。在使用软件预取方式时,当执行预取指令时,处理器需要能够继续执行,也就是能够继续从DCache中读取数据,而不能让预取指令阻碍后面指令的执行,因此需要DCache采用非阻塞结构。
在实现了虚拟存储器(Virtual Memory)的系统中,预取指令可能会引起一些异常(Exception),如发生Page Fault、虚拟地址错误(Virtual Address Fault)或保护违例(Protection Violation)等,现代很多处理器通常都忽略掉预取指令产生的异常。
0x08 多端口Cache
在超标量处理器中,为了提高性能,处理器需要能够在每个周期同时执行多条load/store指令,这就需要一个多端口的DCache,但由于DCache的容量比较大,采用多端口设计,会对芯片的面积和速度带来很大的负面影响,因此就需要采取一些策略解决这个问题,这里介绍三种方法:True Multi-port、Multiple Cache Copies和Multi-banking。
True Multi-port
这也就是最原始的方法,即真的使用一个多端口的SRAM来实现多端口的Cache。在这种设计中,所有在Cache中的控制通路和数据通路都需要进行复制,这就说明,它有两套地址解码器(Address Decoder),使两个端口可以同时寻址Tag SRAM和Data SRAM;有两个多路选择器(Way Mux),用来同时读取两个端口的数据;比较器的数量也需要增加一倍,用来判断两个端口的命中情况;同时还需要两个对齐器(Aligned),用来完成字节或半字的读取等。Tag SRAM与Data SRAM本身不需要复制,但是其中每个Cell都需要同时支持两个并行的读取操作,而并不需要支持两个并行的写端口,因为无法对一个SRAM Cell同时写0和1。下图就是一个SRAM Cell同时支持两个读端口和一个写端口的示意图:
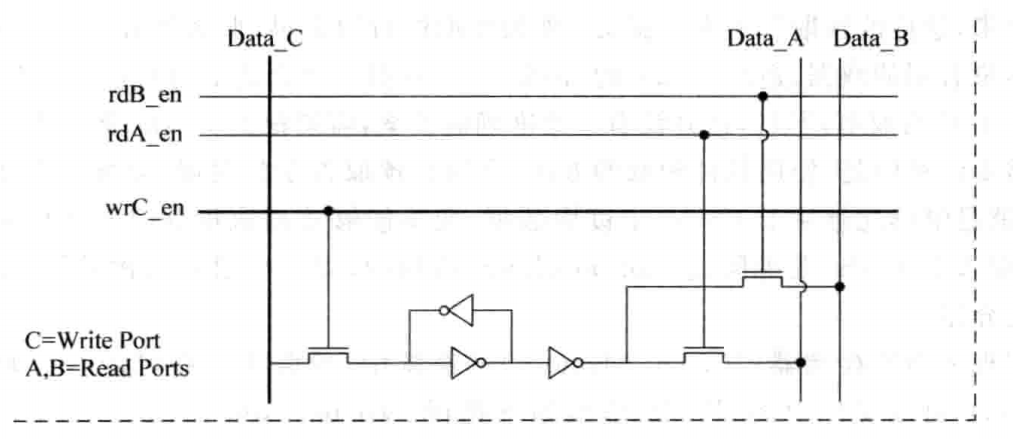
Multiple Cache Copies
这种方式将Tag SRAM和Data SRAM进行了复制,而SRAM不再需要多端口的结构,可以基本消除对处理器周期时间的影响,但是却浪费了过多的面积,而且需要保持两个Cache间的同步,这样的设计过于麻烦,在现代处理器中很少被使用,其工作原理如下:
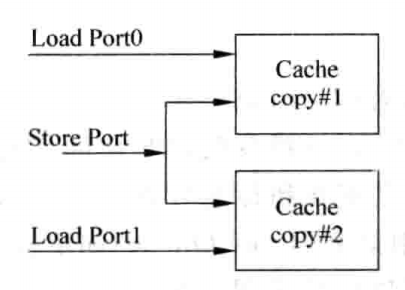
Multi-banking
这种结构被广泛用于现代处理器中,它将Cache划分为几个小的bank,每个bank都只有一个端口,如果在一个时钟周期内,Cache的多个端口上的访问地址位于不同的bank之中,那么这样不会引起任何问题,只有当两个或者多个端口的地址位于同一个bank中时,才会引起冲突,成为bank冲突(Bank Conflict)。
在这种方法中,一个双端口的Cache仍然需要两个地址解码器、两个多路选择器、两套比较器和两个对齐器,但是Data SRAM此时不需要实现多端口结构了,这样就提高了速度,并在一定程序上减少了面积。但由于需要判断Cache的每个端口是否命中,所以Tag SRAM仍然需要提供多个端口同时读取的功能,也就是需要采用多端口SRAM来实现,或者采用将单端口SRAM进行复制的方法,其工作原理如下图所示:
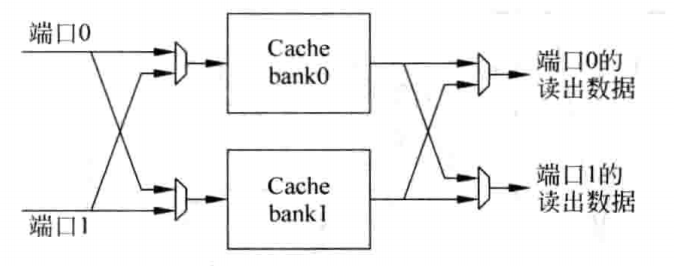
影响这种多端口Cache性能的一个关键因素在于Bank冲突,可以采用多Bank的方式来缓解这个问题,根据空间局部性原理,或许采用地址低位Bank的方式要更合适一些,同时由于每个端口都会访问所有的的Bank,这就需要更多的布线资源,可能会对版图设计带来一定的影响。
0x09 超标量处理器的取指令
如果一个超标量处理器每周期可以同时解码四条指令,这个处理器就成为4-way的超标量处理器,这个处理器每周期应该能够从ICache中至少取得四条指令,这样才能满足后续流水线的需求,如果少于这个值,则会造成后面流水线的浪费。
为了实现这个功能,最简单的方法是让ICache的数据块大小为n个字(假设一条指令长度为一个字),每周期将其全部输出,但这样的前提是处理器送出的指令地址是n字对齐的,在数据块部分就需要实现n个32位的SRAM(假设一个字是32位),一旦地址不对齐,就会导致一个周期无法取出四条指令,平均来说,每周期可以取出2.5条指令,很显然,相比于4-way的处理器而言,这种Cache更适合2-way的处理器,很多处理器正是采用了这种方式。事实上,这种分析较为悲观,因为一般情况下,就算处理器第一次的指令地址不对齐,后续的指令地址一般也会对齐,除非程序中存在较多的分支指令,这就会导致ICache只有很少的机会可以同时输出n条指令。
既然上面的策略存在这个问题,我们不妨进一步扩展上面的策略,最简单的方法是将数据块变大,使其包含8个字,只要取指令的地址不是落在数据块的最后三个字上,就可以在每周期内读取四条指令,这样平均情况每周期可以取出3.25条指令,不过这样增加了Cache Line的大小,在Cache总容量一定的情况,也就意味着减少了Cache Set的数量,这样也可能增大Cache缺失的概率。
同时,如果采用8个32位的SRAM,由于在实际版图设计中,每个SRAM周围都需要摆放一圈保护电路,如果SRAM个数过多,会导致这些保护电路占用过多的面积,同时,从八个SRAM中选出四个字也是一件很浪费电路的事情,因此在实际中,通常采用四个SRAM来实现一个大小为八个字的数据块,实现方式如下图所示:
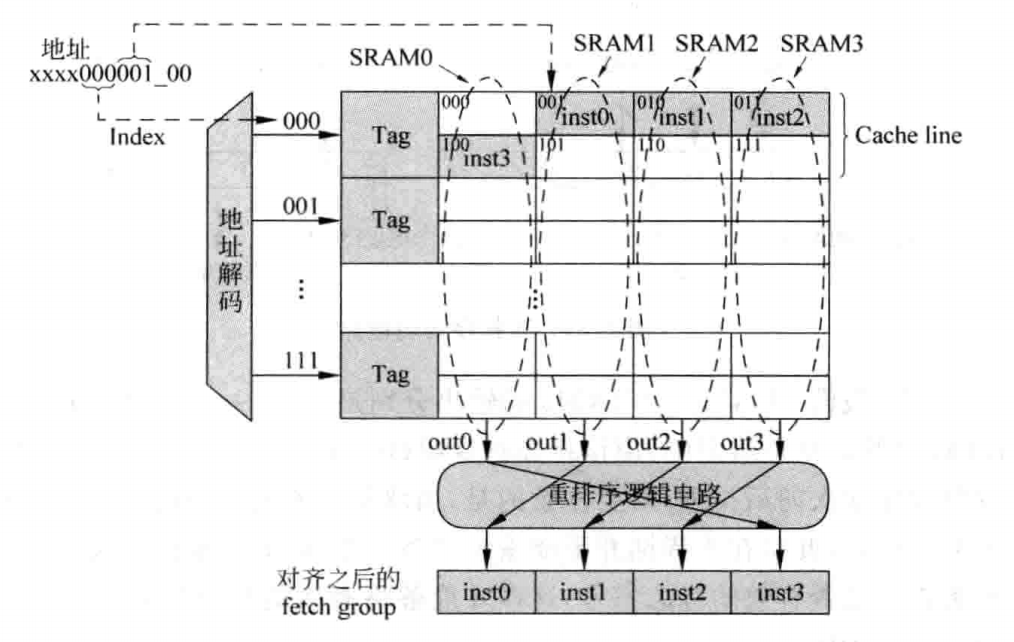
可以看到,上图中一个Cache Line实际上占用了SRAM的两行,由于读取的四条指令必定是相邻的,因此有些SRAM只需要读取第一行,而有些SRAM则只需要读取第二行,并不存在冲突的情况,然后采用一个重排序逻辑电路对SRAM输出的数据进行重排序,使其满足最原始的指令顺序,重排序逻辑如下:
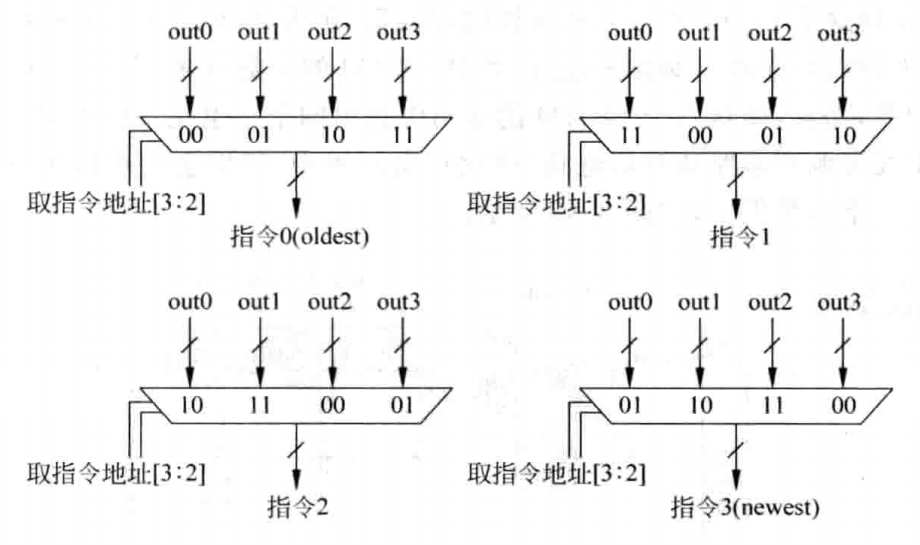
可以看到,当取指令地址[3:2]的值为00时,四个Mux的输出分别为out0 out1 out2 out3;为01时,分别为out1 out2 out3 out0,为10时;分别为out2 out3 out0 out1;为11时,分别为out3 out0 out1 out2。但当指令地址指向Cache Line中的最后三条指令中的某一个时,此时并不能输出四条指令,因此,重排序逻辑电路中还需要加入指示每条指令是否有效的标志信号,这样才能够将指令写入到后续的指令缓存(Instruction Buffer)中。
大佬牛逼
博主写得很棒,有个问题想请教一下,我想问下multibanking里的bank conflict一般应该怎么解决?是让conflict的访存操作停下等待吗?
是的