
- 1:0x00 综述
- 2:0x01 最简单的方法——直接使用上次分支的结果
- 3:0x02 基于两位饱和计数器的分支预测
- 4:0x03 基于局部历史的分支预测
- 5:0x04 基于全局历史的分支预测
- 6:0x05 竞争的分支预测
0x00 综述
本文主要参考了姚永斌的《超标量处理器设计》
在现代处理器中,动态分支预测技术在提升处理器IPC方面非常重要,这篇文章总结了常见的各种动态分支预测方法。
0x01 最简单的方法——直接使用上次分支的结果
我们考虑下面的例子:
for(i = 0;i < 1000;i++)
{
一些语句
}我们假设第一次结果为不跳转,那么第二次、第三次……第1000次预测为跳转,很明显,在使用该方法时,只有两次预测错误(即第一次和最后一次),因此预测的成功率为998/1000=99.8%。
但假设对于一个分支,其方向变化规律为(T表示跳转,N表示不跳转):TNTNTNTNTN……,那么将会导致每次预测都失败,其成功率为0%。
由于这种方法的准确度波动过大,难以被接受,因此并没有在现代处理器中被采纳。目前应用最广泛的分支预测方法都是基于两位饱和计数器的方法。
0x02 基于两位饱和计数器的分支预测
两位饱和计数器,顾名思义,用两个比特位来存储预测结果,而这两个比特位分别表示如下四种状态:
- Strongly taken:计数器处于饱和状态,分支指令本次会被预测发生跳转
- Weakly taken:计数器处于不饱和状态,分支指令本次会被预测发生跳转
- Weakly not taken:计数器处于不饱和状态,分支指令本次会被预测不发生跳转
- Strongly not token:计数器处于饱和状态,分支指令本次会被预测不发生跳转
而这四种方法可以构成一个状态机,该状态机最一般的形式如下图所示:
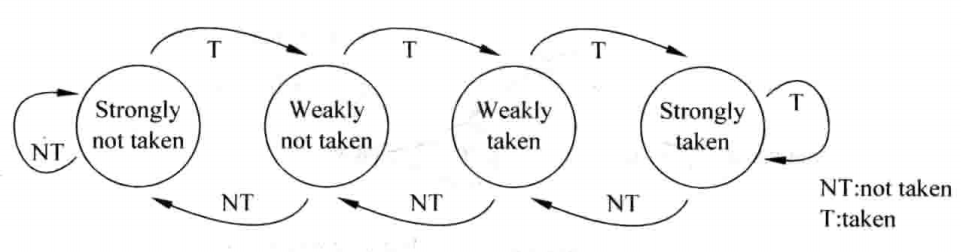
该方法中含有“饱和计数器”这几个字,其中“饱和”的含义是,一旦进入Strongly,只要新的跳转状态与当前状态相符,当前状态就不会发生改变,而所谓“计数器”是指,这几种状态是按序排列的,并根据新的跳转状态进行+1、-1操作(在不饱和的情况下)。
该状态机的初始状态通常采用Strongly not taken或者Weakly not taken。
可以使用格雷码对状态机进行编码,保证在状态转换时每次只有一位发生变化,这样可以减少出错的概率,并降低功耗。
我们还是观察这个例子:
for(i = 0;i < 1000;i++)
{
一些语句
}可以看到,假设状态机初态是Weakly not token时,利用饱和计数器方法,其预测准确率是99.8%。
这种方式的优点在于,对于偶尔的、瞬间的分支方向变化不敏感(比如只是偶尔出现一次方向的改变,预测值很可能不会改变),不过对于TNTN型的分支而言,其还是存在成功率过低(根据初态不同,最差为0%,最好为50%)的问题。
分支预测一般都是以PC值为基础,即将每个PC值都对应一个两位的饱和计数器,但是这样做的话,两位饱和计数器存储器会过大。考虑到并不是所有的指令都是分支指令,通常我们会从PC的中部取一段作为两位饱和计数器存储器的地址,该存储器叫做PHT(Pattern History Table),就像下图一样:
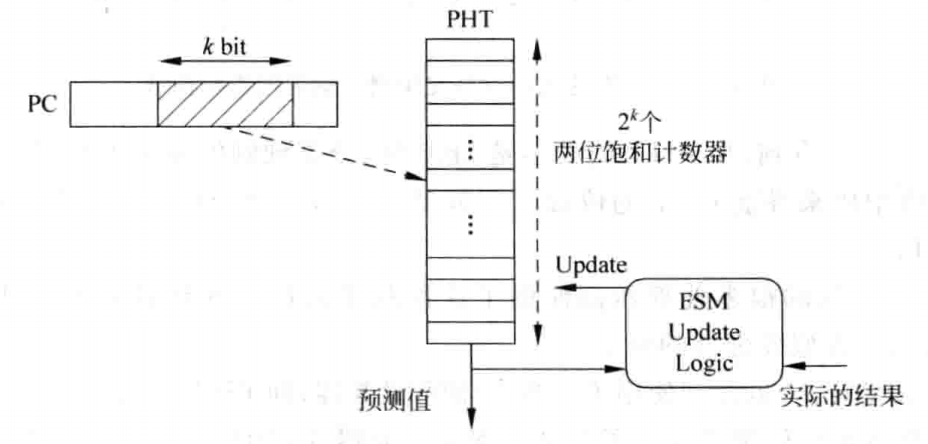
但是这样做,可能会导致多条分支指令共享一个PHT项,这会导致别名问题,会降低分支预测的准确率。为了解决这个问题,可以采用哈希的方法,对PC值进行哈希处理后再去寻址PHT。
这种分支预测方法很难达到98%以上的正确率,因此现代处理器都不会直接使用这种方法了。
0x03 基于局部历史的分支预测
上面讨论过,对于TNTN型这种有规律的分支,两位饱和计数器的表现还是很差,因此我们可以考虑利用一条指令过去一段时间内的跳转历史记录,提取规律来进行分支预测,这样势必会对于这种情况的预测准确度。
为了实现这样的想法,我们需要分支历史寄存器(Branch History Register, BHR)。对于一条分支指令,我们只需将其每次的结果移入BHR寄存器,就可以记录这条分支指令的历史状态了,然后我们只需将BHR的值作为PHT的索引,就可以针对每一种历史状态分别做出预测。但是很明显,这种方法的预测准确度和BHR的长度密切相关,假设BHR的长度短于跳转序列重复周期,这将会导致预测准确率大大下跌,但是BHR的长度过大,会导致PHT过大,同时也会延长找出规律的时间,这对于分支预测的准确度也是有负面影响的。因此在这种方法中,需要对BHR的位宽进行trade off。
上面的实现方法的一个大前提就是,每条分支指令都有自己对应的BHR和PHT,这样需要非常大的存储空间,是不现实的。
BHR组合在一起的表称作分支历史寄存器表(Branch History Register Table, BHRT或BHT),实际一般都会将PC的哈希值作为BHT的索引,通过对BHR进行复用从而缩小BHT的体积。
PHT的体积也是一个大问题,在0x01的方法中,每一条指令仅仅对应一个2bit饱和计数器,而这里却对应若干个2bit饱和计数器,其数量和BHR的位宽直接相关,也就是说PHT变成了PHTs,为了解决这个问题,我们可以让所有的指令共用一个PHT,然后将PC的值与BHT输出的值进行处理(如拼接、XOR、哈希等方法)作为PHT的索引,即可大大缩小PHT的大小。
0x04 基于全局历史的分支预测
在0x03中,我们在分支预测时,将一条指令的局部历史也考虑了进来,大大增加了预测的准确性,但是,我们还可以利用某条指令前面若干条分支指令的执行结果进行预测,这或许会进一步提高预测的准确度,这种方法叫做基于全局历史(Global History)的分支预测方法。
举一个很简单的例子:
if(aa == 2) //b1
{
aa = 0;
}
if(bb == 2) //b2
{
bb = 0;
}
if(aa != bb) //b3
{
一些语句
}可以看到,如果分支b1和b2都执行了,那么分支b3就不会执行,只依靠分支b3的局部历史进行分支预测,是永远不会发现这个规律的,因此需要在预测b3时同时考虑b1与b2的跳转结果,为了实现方法,我们需要一个全局历史寄存器(Global History Register, GHR),这是一个有限位宽的寄存器,来记录最近若干条分支指令的跳转结果,每当遇到一条跳转指令时,就会将其结果移入GHR。
使用GHR最简单的方法,便是采用PHTs,由PC选择具体的PHT,再由GHR的值选择PHT的某一项,但是这存在于0x03相同的问题:PHT过大,因此我们可以采用和0x03类似的优化方法:只使用一个PHT,并将GHR的值与PC做某种混合处理后再作为PHT的索引,这样便大大减少了PHT使用的存储空间。
我们可以注意到,由于这种方法仅考虑了全局历史,却没有考虑局部历史,因此对于TNTN这种有规律的分支,反而可能会出现预测准确度下降的问题。其本质原因在于有些分支指令适合使用基于全局历史的分支预测方法,而另一些则更适合使用句历史的分支预测方法,这就引出了下面的方法。
0x05 竞争的分支预测
在这种方法中,我们综合使用各种不同的分支预测方法,例如在Alpha 21264处理器中,就采用了一种自适应的分支预测方法:
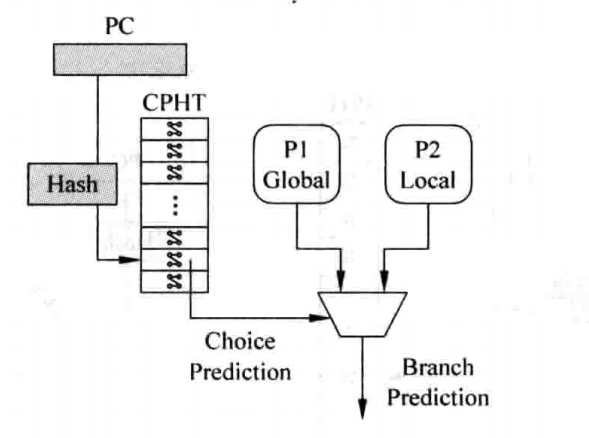
更详细的图如下:
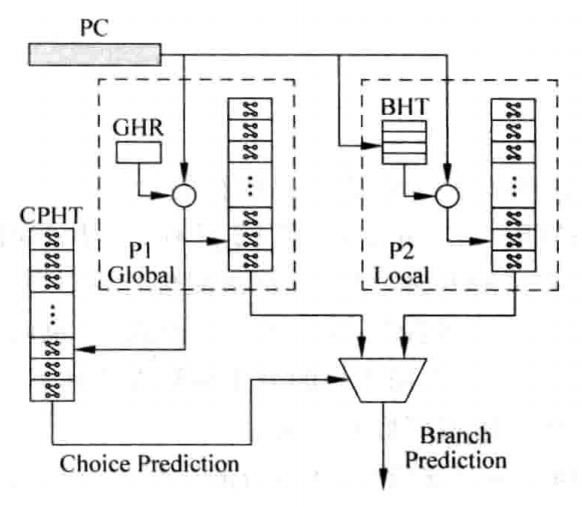
其中,P1表示基于全局历史的分支预测方法,P2表示基于局部历史的分支预测方法。
CPHT(Choice PHT)是由分支的PC值来寻址的一个表格,类似于PHT,其中每一项由两位的饱和计数器组成,而状态机的转移条件不是某条指令本身的跳转结果,而是P1与P2的预测成功与否,四个状态分别表示强和弱的使用P1、P2。
事实上,Alpha 21264只使用GHR作为CPHT的寻址地址,这样实际上就丢失了每条分支指令的地址信息,因此当两条不同的分支指令对应的GHR相同时,就会造成冲突,降低分支预测的准确度。